Sergio Luján - Programación en Internet: Clientes Web
Aquí puedes leer online Sergio Luján - Programación en Internet: Clientes Web texto completo del libro (historia completa) en español de forma gratuita. Descargue pdf y epub, obtenga significado, portada y reseñas sobre este libro electrónico. Año: 2001, Género: Ordenador. Descripción de la obra, (prefacio), así como las revisiones están disponibles. La mejor biblioteca de literatura LitFox.es creado para los amantes de la buena lectura y ofrece una amplia selección de géneros:
Novela romántica
Ciencia ficción
Aventura
Detective
Ciencia
Historia
Hogar y familia
Prosa
Arte
Política
Ordenador
No ficción
Religión
Negocios
Niños
Elija una categoría favorita y encuentre realmente lee libros que valgan la pena. Disfrute de la inmersión en el mundo de la imaginación, sienta las emociones de los personajes o aprenda algo nuevo para usted, haga un descubrimiento fascinante.

- Libro:Programación en Internet: Clientes Web
- Autor:
- Genre:
- Año:2001
- Índice:4 / 5
- Favoritos:Añadir a favoritos
- Tu marca:
Programación en Internet: Clientes Web: resumen, descripción y anotación
Ofrecemos leer una anotación, descripción, resumen o prefacio (depende de lo que el autor del libro "Programación en Internet: Clientes Web" escribió él mismo). Si no ha encontrado la información necesaria sobre el libro — escribe en los comentarios, intentaremos encontrarlo.
Sergio Luján: otros libros del autor
¿Quién escribió Programación en Internet: Clientes Web? Averigüe el apellido, el nombre del autor del libro y una lista de todas las obras del autor por series.












Programación en Internet: Clientes Web — leer online gratis el libro completo
A continuación se muestra el texto del libro, dividido por páginas. Sistema guardar el lugar de la última página leída, le permite leer cómodamente el libro" Programación en Internet: Clientes Web " online de forma gratuita, sin tener que buscar de nuevo cada vez donde lo dejaste. Poner un marcador, y puede ir a la página donde terminó de leer en cualquier momento.
Tamaño de fuente:
Intervalo:
Marcador:
Arquitecturas cliente/servidor
Las aplicaciones web son un tipo especial de aplicaciones cliente/servidor. Antes de aprender a programar aplicaciones web conviene conocer las características básicas de las arquitecturas cliente/servidor.
Índice General
1.1. Introducción
Cliente/servidor es una arquitectura de red en la que cada ordenador o proceso en la red es cliente o servidor . Normalmente, los servidores son ordenadores potentes dedicados a gestionar unidades de disco (servidor de ficheros), impresoras (servidor de impresoras), tráfico de red (servidor de red), datos (servidor de bases de datos) o incluso aplicaciones (servidor de aplicaciones), mientras que los clientes son máquinas menos potentes y usan los recursos que ofrecen los servidores.
Esta arquitectura implica la existencia de una relación entre procesos que solicitan servicios ( clientes ) y procesos que responden a estos servicios ( servidores ). Estos dos tipos de procesos pueden ejecutarse en el mismo procesador o en distintos.
La arquitectura cliente/servidor implica la realización de aplicaciones distribuidas. La principal ventaja de esta arquitectura es que permite separar las funciones según su servicio, permitiendo situar cada función en la plataforma más adecuada para su ejecución. Además, también presenta las siguientes ventajas:
- Las redes de ordenadores permiten que múltiples procesadores puedan ejecutar partes distribuidas de una misma aplicación, logrando concurrencia de procesos.
- Existe la posibilidad de migrar aplicaciones de un procesador a otro con modificaciones mínimas en los programas.
- Se obtiene una escalabilidad de la aplicación. Permite la ampliación horizontal o vertical de las aplicaciones. La escalabilidad horizontal se refiere a la capacidad de añadir o suprimir estaciones de trabajo que hagan uso de la aplicación (clientes), sin que afecte sustancialmente al rendimiento general. La escalabilidad vertical permite la migración hacia servidores de mayor o menor capacidad y velocidad o de un tipo diferente.
- Posibilita el acceso a los datos independientemente de donde se encuentre el usuario.
1.2. Separación de funciones
La arquitectura cliente/servidor nos permite la separación de funciones en tres niveles, tal como se muestra en la Figura 1.1:
- Lógica de presentación . La presentación de los datos es una función independiente del resto.
- Lógica de negocio (o aplicación) . Los flujos de trabajo pueden cambiarse según las necesidades existentes de un procesador a otro.
- Lógica de datos . La gestión de los datos debe ser independiente para poder ser distribuida según las necesidades de la empresa en cada momento.
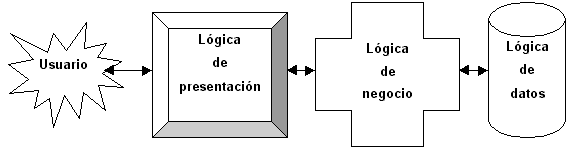
Figura 1.1: Separación de funciones
Si un sistema distribuido se diseña correctamente, los tres niveles anteriores pueden distribuirse y redistribuirse independientemente sin afectar al funcionamiento de la aplicación.
1.3. Modelos de distribución en aplicaciones cliente/servidor
Según como se distribuyan las tres funciones básicas de una aplicación (presentación, negocio y datos) entre el cliente y el servidor, podemos contemplar tres modelos: presentación distribuida, aplicación distribuida y datos distribuidos.
1.3.1. Presentación distribuida
El cliente sólo mantiene la presentación, el resto de la aplicación se ejecuta remotamente (Figura 1.2). La presentación distribuida, en su forma más simple, es una interfaz gráfica de usuario a la que se le pueden acoplar controles de validación de datos, para evitar la validación de los mismos en el servidor.

Figura 1.2: Presentación distribuida
1.3.2. Aplicación distribuida
Es el modelo que proporciona máxima flexibilidad, puesto que permite tanto a servidor como a cliente mantener la lógica de negocio realizando cada uno las funciones que le sean más propias, bien por organización, o bien por mejora en el rendimiento del sistema (Figura 1.3).

Figura 1.3: Aplicación distribuida
1.3.3. Datos distribuidos
Los datos son los que se distribuyen, por lo que la lógica de datos es lo que queda separada del resto de la aplicación (Figura 1.4). Se puede dar de dos formas: ficheros distribuidos o bases de datos distribuidas.

Figura 1.4: Datos distribuidos
1.4. Arquitecturas de dos y tres niveles
La diferencia entre las aplicaciones de dos y tres niveles estriba en la forma de distribución de la aplicación entre el cliente y el servidor.
Una arquitectura de dos niveles está basada en un sistema gestor de bases de datos donde el cliente mantiene la lógica de la presentación, negocio, y de acceso a los datos, y el servidor únicamente gestiona los datos. Suelen ser aplicaciones cerradas que supeditan la lógica de los procesos cliente al gestor de base de datos que se está usando.
En las arquitecturas de tres niveles, la lógica de presentación, la lógica de negocio y la lógica de datos están separadas, de tal forma que mientras la lógica de presentación se ejecutará normalmente en la estación cliente, la lógica de negocio y la de datos pueden estar repartidas entre distintos procesadores.
El objetivo de aumentar el número de niveles en una aplicación distribuida es lograr una mayor independencia entre un nivel y otro, lo que facilita la portabilidad en entornos heterogéneos.
1.5. Descripción de un sistema cliente/servidor
Un sistema cliente/servidor suele presentar las siguientes características:
- Una combinación de la parte cliente (también llamada front-end ) que interactúa con el usuario (hace de interfaz entre el usuario y el resto de la aplicación) y la parte servidor (o back-end) que interactúa con los recursos compartidos (bases de datos, impresoras, módems).
- La parte cliente y servidor tienen diferentes necesidades de recursos a la hora de ejecutarse: velocidad de procesador, memoria, velocidad y capacidad de los discos duros, dispositivos de entrada/salida, etc.
- El entorno suele ser heterogéneo y multivendedor. El hardware y sistema operativo del cliente y el servidor suelen diferir. El cliente y el servidor se suelen comunicar a través de unas API para acceder a bases de datos).
- Normalmente la parte cliente se implementa haciendo uso de una inter- faz gráfica de usuario, que permite la introducción de datos a través de teclado, ratón, lápiz óptico, etc.

 Sergio Luján Mora
Sergio Luján Mora
Ingeniero en Informática por la Universidad de Alicante. Ha impartido diversos cursos sobre Internet y las diversas tecnologías que se emplean en la programación de aplicaciones web (HTML, JavaScript, ASP y Java).
Durante un año ha trabajado en el Laboratorio Multimedia (mmlab) de la Universidad de Alicante, desarrollando aplicaciones para Internet e intranets.
Desde 1999 forma parte del Departamento de Lenguajes y Sistemas Informáticos de la Universidad de Alicante. Las asignaturas que imparte en la actualidad son Programación en Internet y Programación y Estructuras de Datos .
Tamaño de fuente:
Intervalo:
Marcador:
Libros similares «Programación en Internet: Clientes Web»
Mira libros similares a Programación en Internet: Clientes Web. Hemos seleccionado literatura similar en nombre y significado con la esperanza de proporcionar lectores con más opciones para encontrar obras nuevas, interesantes y aún no leídas.
Discusión, reseñas del libro Programación en Internet: Clientes Web y solo las opiniones de los lectores. Deja tus comentarios, escribe lo que piensas sobre la obra, su significado o los personajes principales. Especifica exactamente lo que te gustó y lo que no te gustó, y por qué crees que sí.