Rudolph Russell - Machine Learning - Guía Paso a Paso Para Implementar Algoritmos De Machine Learning Con Python
Aquí puedes leer online Rudolph Russell - Machine Learning - Guía Paso a Paso Para Implementar Algoritmos De Machine Learning Con Python texto completo del libro (historia completa) en español de forma gratuita. Descargue pdf y epub, obtenga significado, portada y reseñas sobre este libro electrónico. Año: 2018, Género: Ordenador / Ciencia. Descripción de la obra, (prefacio), así como las revisiones están disponibles. La mejor biblioteca de literatura LitFox.es creado para los amantes de la buena lectura y ofrece una amplia selección de géneros:
Novela romántica
Ciencia ficción
Aventura
Detective
Ciencia
Historia
Hogar y familia
Prosa
Arte
Política
Ordenador
No ficción
Religión
Negocios
Niños
Elija una categoría favorita y encuentre realmente lee libros que valgan la pena. Disfrute de la inmersión en el mundo de la imaginación, sienta las emociones de los personajes o aprenda algo nuevo para usted, haga un descubrimiento fascinante.

- Libro:Machine Learning - Guía Paso a Paso Para Implementar Algoritmos De Machine Learning Con Python
- Autor:
- Genre:
- Año:2018
- Índice:5 / 5
- Favoritos:Añadir a favoritos
- Tu marca:
Machine Learning - Guía Paso a Paso Para Implementar Algoritmos De Machine Learning Con Python: resumen, descripción y anotación
Ofrecemos leer una anotación, descripción, resumen o prefacio (depende de lo que el autor del libro "Machine Learning - Guía Paso a Paso Para Implementar Algoritmos De Machine Learning Con Python" escribió él mismo). Si no ha encontrado la información necesaria sobre el libro — escribe en los comentarios, intentaremos encontrarlo.
Rudolph Russell: otros libros del autor
¿Quién escribió Machine Learning - Guía Paso a Paso Para Implementar Algoritmos De Machine Learning Con Python? Averigüe el apellido, el nombre del autor del libro y una lista de todas las obras del autor por series.












Machine Learning - Guía Paso a Paso Para Implementar Algoritmos De Machine Learning Con Python — leer online gratis el libro completo
A continuación se muestra el texto del libro, dividido por páginas. Sistema guardar el lugar de la última página leída, le permite leer cómodamente el libro" Machine Learning - Guía Paso a Paso Para Implementar Algoritmos De Machine Learning Con Python " online de forma gratuita, sin tener que buscar de nuevo cada vez donde lo dejaste. Poner un marcador, y puede ir a la página donde terminó de leer en cualquier momento.
Tamaño de fuente:
Intervalo:
Marcador:
Machine Learning
Guía Paso a Paso Para Implementar
Algoritmos De Machine Learning Con Python
Rudolph Russell
© Copyright 2018 Rudolph Russell – Todos los derechos reservados.
Si te gustaría compartir este libro con otra persona, por favor compra una copia adicional por cada recipiente. Gracias por respetar el arduo trabajo de este autor. De otra forma, la transmisión, duplicación o reproducción alguna del siguiente trabajo incluyendo información específica será considerada un acto ilegal indiferentemente si es hecho electrónicamente o por impresión. Esto se extiende a crear una copia secundaria o terciaria, o una copia grabada y sola es permitida con un consenso escrito por parte del editor. Todos los derechos adicionales son reservados.
Tabla de Contenido
Si pregunto acerca del “Machine Learning” probablemente imaginarás un robot o algo como el Exterminador. En realidad, el Machine Learning no solo está involucrado en la robótica, pero además en muchas otras aplicaciones. También puedes imaginar algo como filtros de spam al ser una de las primeras aplicaciones en Machine Learning el cual ayuda a mejorar la vida de millones de personas. En este capítulo, te presentaré lo que es el Machine Learning, y como funciona.
El Machine Learning es la práctica de programación de computadoras para aprender de los datos. En el ejemplo de arriba, el programa fácilmente podrá determinar si lo dado es importante o si es “spam” (correo electrónico no deseado). En el Machine Learning, los datos son conocidos como conjuntos de capacitación o ejemplos.
Asumamos que quisieras escribir el programa filtro sin usar métodos de Machine Learning. En este caso, tendrás que seguir los siguientes pasos:
Al principio, echarías un vistazo a lo cómo se ven los correos electrónicos no deseados. Podrías seleccionarlos por las palabras o frases que usan, como “tarjeta de debido”, “gratis”, y muchas más, y además de patrones que son usados en los nombres de los remitentes o en el cuerpo del correo.
.Segundo, escribirías un algoritmo para detectar los patrones que hayas visto, y luego el software indicaría los correo electrónicos como “no deseado” si un numero de esos patrones es encontrado.
Finalmente, probarías el programa, y reharías los primeros dos pasos hasta que los resultados sean suficientemente buenos.
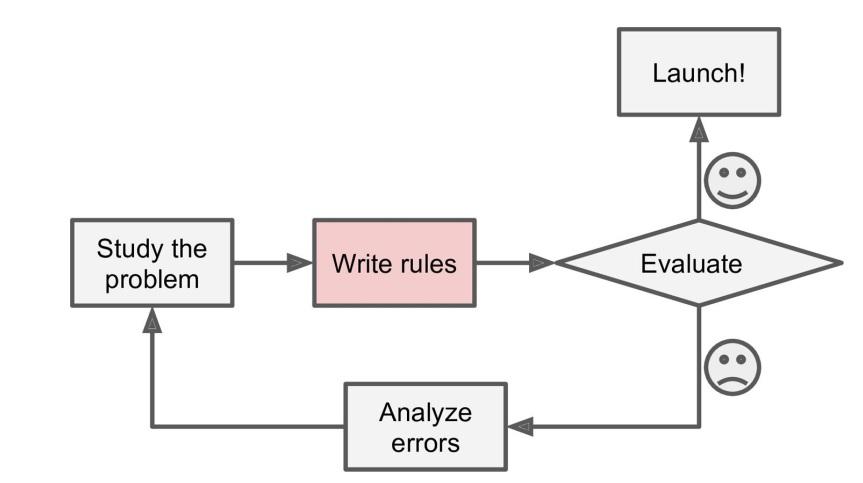
Porque el programa no es software, contienen una lista muy larga de reglas que son difíciles de mantener. Pero si desarrollas el mismo software usando AA (Machine Learning), podrás mantenerlo adecuadamente.
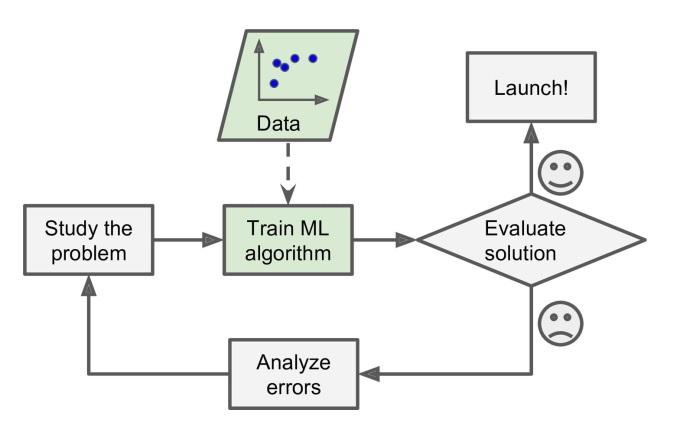
Adicionalmente, los remitentes de los correos electrónicos pueden cambiar las plantillas de los correos para que una palabra como “4You” ahora sea “para ti”, ya que sus correos han sido determinados como “no deseados”. Los programas que usan técnicas tradicionales necesitarían ser actualizados, lo que significa que, si hubiese otros cambios, necesitarías actualizar tus códigos otra vez, otra vez, y otra vez.
Por otro lado, un programa que usa técnicas de AA automáticamente detectarán estos cambios hechos por los usuarios, y comenzará a indicarlos como “no deseados” sin la necesidad de que lo hagas manualmente.
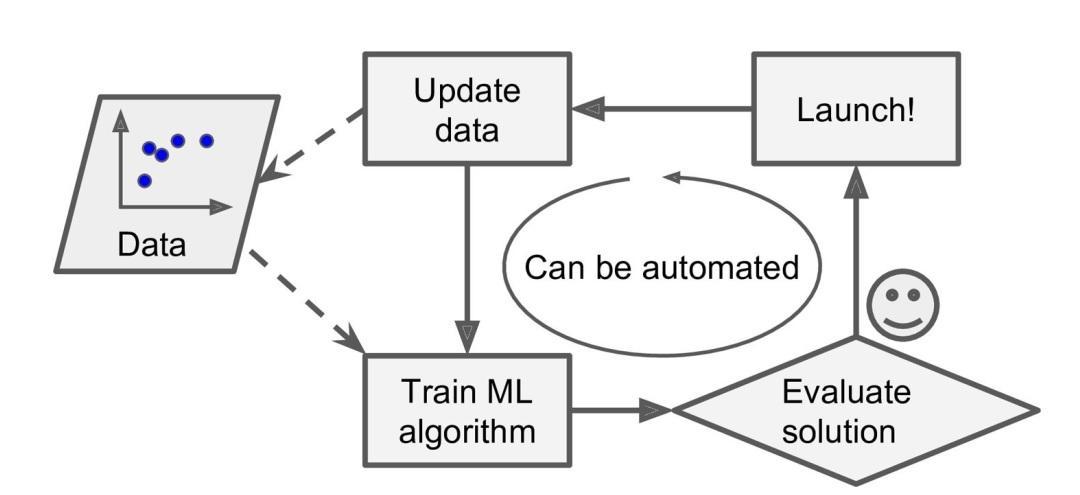 Además, podemos usar AA para resolver problemas que son muy complejos los softwares que no usan AA. Por ejemplo, reconocimiento de discurso, cuando tú dices “uno” o “dos”, el programa debería poder distinguir la diferencia. Entonces, para esta tarea, deberás desarrollar un algoritmo que mide el sonudo.
Además, podemos usar AA para resolver problemas que son muy complejos los softwares que no usan AA. Por ejemplo, reconocimiento de discurso, cuando tú dices “uno” o “dos”, el programa debería poder distinguir la diferencia. Entonces, para esta tarea, deberás desarrollar un algoritmo que mide el sonudo.
Al final, el Machine Learning nos ayudará a aprender, y los algoritmos del Machine Learning nos puede ayudar a ver lo que hemos aprendidos.
- Cuando tengas un problema que requiera de largas listas de reglas para encontrar la solución. En este caso, las técnicas de Machine Learning pueden simplificar tu código y mejorar el desempeño.
- Problemas muy complejos para los que no haya solución con un enfoque tradicional.
- Ambientes no estables: softwares con Machine Learning se pueden adaptar a nuevos datos.
Hay diferentes tipos de sistemas de Machine Learning. Podemos dividirlos en categorías dependiendo si:
- Han sido capacitados con humanos o no
- Supervisado
- Sin supervisión
- Semi-supervisado
- Machine Learning de Refuerzo
- Si pueden aprender de forma incrementada
- Si pueden trabajar simplemente combinando nuevos puntos de datos, o si pueden detectar nuevos patrones en los datos, y luego construirán un modelo
Podemos clasificar los sistemas de Machine Learning de acuerdo al tipo y a la cantidad de supervisión humana durante la capacitación. Podrás encontrar 4 categorías principales, como hemos explicado antes.
Machine Learning Supervisado
Machine Learning sin Supervisión
Machine Learning Semi-Supervisado
Machine Learning de Refuerzo
En este tipo de sistema de Machine Learning los datos con que tu alimentas el algoritmo, con la solución deseada, son referidos como “labels” (etiquetas).
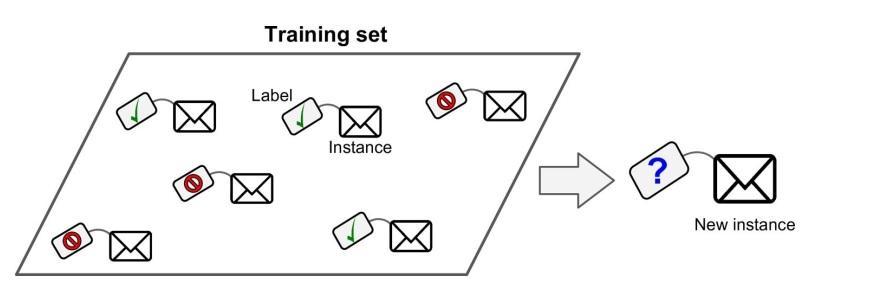
El Machine Learning supervisado agrupa tareas de clasificación. El programa de arriba es un buen ejemplo de esto porque ha sido capacitado con muchos correos electrónicos al mismo tiempo que sus clases
Otro ejemplo es predecir un valor numérico como el precio de un apartamento, dados un numero de características (ubicación, número de habitaciones, instalaciones), llamados predictores; este tipo de tarea es llamado regresión.
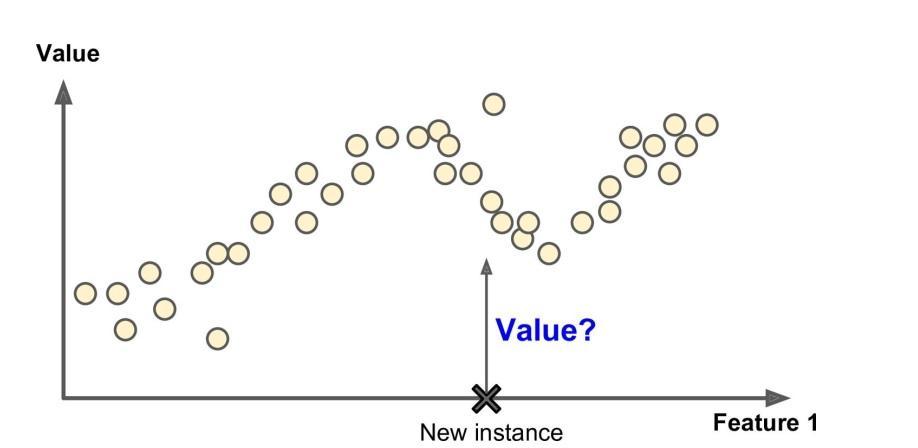 Debes tener en cuenta que algunos algoritmos de regresión puden ser usados para clasificación también, y viceversa.
Debes tener en cuenta que algunos algoritmos de regresión puden ser usados para clasificación también, y viceversa.
K-nearest neighbors (KNN, vecinos más cercanos K)
Red Neural
Máquinas de soporte de vectores
Regresión logística
Arboles de decisiones y bosques aleatorios
En este tipo de sistemas de Machine Learning, puedes suponer que los datos están sin etiqueta.
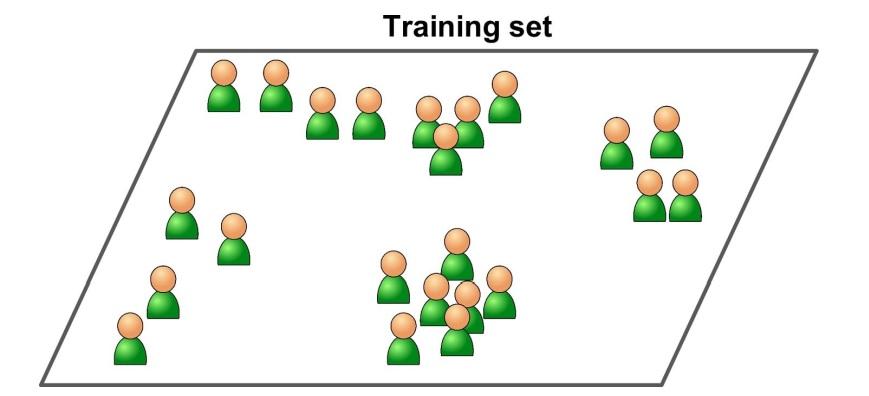
Agrupamiento (Clustering): Medios k, análisis de agrupamiento jerárquico
Machine Learning de Asociación de Regla: Eclat y A priori
Visualización y Reducción de Dimensionalidad: Núcleo PCA, distribuido de t PCA.
Como ejemplo, supongamos que tienes muchos datos en el uso visitante de uno de nuestros algoritmos para detecar grupos con visitantes similares. Podría encontrar que el 65% de tus visitantes son masculinos a quienes les encanta ver películas en las noches, mientras que el 30% ve obras en las noches; en este caso, usando un algoritmo de agrupamiento, dividirá cada grupo en sub grupos.
Tamaño de fuente:
Intervalo:
Marcador:
Libros similares «Machine Learning - Guía Paso a Paso Para Implementar Algoritmos De Machine Learning Con Python»
Mira libros similares a Machine Learning - Guía Paso a Paso Para Implementar Algoritmos De Machine Learning Con Python. Hemos seleccionado literatura similar en nombre y significado con la esperanza de proporcionar lectores con más opciones para encontrar obras nuevas, interesantes y aún no leídas.
Discusión, reseñas del libro Machine Learning - Guía Paso a Paso Para Implementar Algoritmos De Machine Learning Con Python y solo las opiniones de los lectores. Deja tus comentarios, escribe lo que piensas sobre la obra, su significado o los personajes principales. Especifica exactamente lo que te gustó y lo que no te gustó, y por qué crees que sí.